
我們都曾遇到過在某個時候不得不從網站中提取數據的情況。
例如,在處理新帳戶或廣告系列時,您可能沒有可用于創建廣告的數據或信息。
在理想情況下,我們會以易于導入的格式(例如 CSV、Excel 電子表格或 Google 表格)為我們提供所需的所有內容、登錄頁面和相關信息。(或者至少,提供我們需要的選項卡式數據,可以將其導入上述格式之一。)
但這并不總是這樣。
那些缺乏網絡抓取工具的人——或者缺乏使用 Python 之類的東西來幫助完成任務的編碼知識——可能不得不求助于手動復制和粘貼可能成百上千個條目的繁瑣工作。
在最近的一份工作中,我的團隊被要求:
- 轉到客戶的網站。
- 下載分布在 15 個不同頁面上的 150 多種新產品。
- 將每個產品的產品名稱和著陸頁網址復制并粘貼到電子表格中。
現在,您可以想象,如果我們只是這樣做并手動執行任務,該任務會有多長。
這不僅耗時,而且有人手動瀏覽那么多項目和頁面,并且必須逐個產品地復制和粘貼數據,犯一兩個錯誤的可能性非常高。
然后將需要更多時間來審查文檔并確保它沒有錯誤。
一定有更好的方法。
好消息:有!讓我告訴你我們是怎么做到的。
什么是 IMPORTXML?
輸入谷歌表格。我希望您了解一下 IMPORTXML 函數。
根據 Google 的支持頁面,IMPORTXML“從各種結構化數據類型中導入數據,包括 XML、HTML、CSV、TSV 以及 RSS 和 ATOM XML 提要。”
本質上,IMPORTXML 是一種允許您從網頁中抓取結構化數據的功能——無需編碼知識。
例如,可以快速輕松地提取頁面標題、描述或鏈接等數據,但也可以提取更復雜的信息。
IMPORTXML 如何幫助抓取網頁元素?
該函數本身非常簡單,只需要兩個值:
- 我們打算從中提取或抓取信息的網頁的 URL。
- 以及包含數據的元素的 XPath。
XPath 代表 XML 路徑語言,可用于在 XML 文檔中瀏覽元素和屬性。
例如,要從 https://en.wikipedia.org/wiki/Moon_landing 中提取頁面標題,我們將使用:
=IMPORTXML(“https://en.wikipedia.org/wiki/Moon_landing”, “//title”)
這將返回值:Moon landing – Wikipedia。
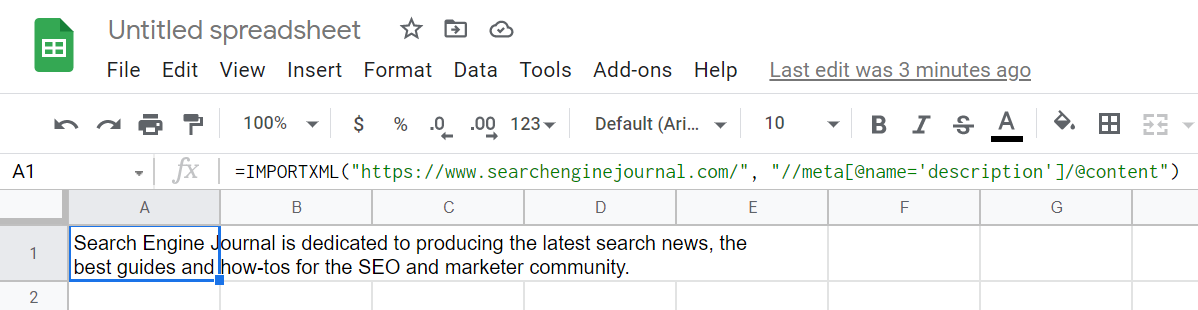
或者,如果我們正在尋找頁面描述,試試這個:
=IMPORTXML(“https://www.searchenginejournal.com/”,”//meta[@name=’description’]/@content”)
以下是一些最常見和最有用的 XPath 查詢的候選清單:
- 頁面標題://標題
- 頁面元描述://meta[@name=’description’]/@content
- 頁面 H1://h1
- 頁面鏈接://@href
查看 IMPORTXML 的實際應用
自從在 Google 表格中發現 IMPORTXML 以來,它真正成為我們許多日常任務自動化的秘密武器之一,從活動和廣告創建到內容研究等等。
此外,該函數與其他公式和附加組件相結合,可用于更高級的任務,否則這些任務將需要復雜的解決方案和開發,例如用 Python 構建的工具。
但在本例中,我們將以最基本的形式查看 IMPORTXML:從網頁中抓取數據。
讓我們看一個實際的例子。
想象一下,我們被要求為 Search Engine Journal 創建一個活動。
他們希望我們在網站的 PPC 部分宣傳最近發表的 30 篇文章。
您可能會說,這是一項非常簡單的任務。
不幸的是,編輯們無法向我們發送數據,并請我們參考該網站以獲取設置活動所需的信息。
正如我們文章開頭提到的,一種方法是打開兩個瀏覽器窗口——一個是網站,另一個是 Google 表格或 Excel。然后我們將開始逐條復制和粘貼信息,逐個鏈接。
但是在 Google 表格中使用 IMPORTXML,我們可以在很短的時間內獲得相同的輸出,幾乎沒有犯錯的風險。
就是這樣。
第 1 步:從全新的 Google 表格開始
首先,我們打開一個新的空白 Google 表格文檔:
第 2 步:添加您需要抓取的內容
添加我們要從中抓取信息的頁面(或頁面)的 URL。
在我們的例子中,我們從 https://www.searchenginejournal.com/category/pay-per-click/ 開始:
截取自 Google 表格的屏幕截圖,2021 年 7 月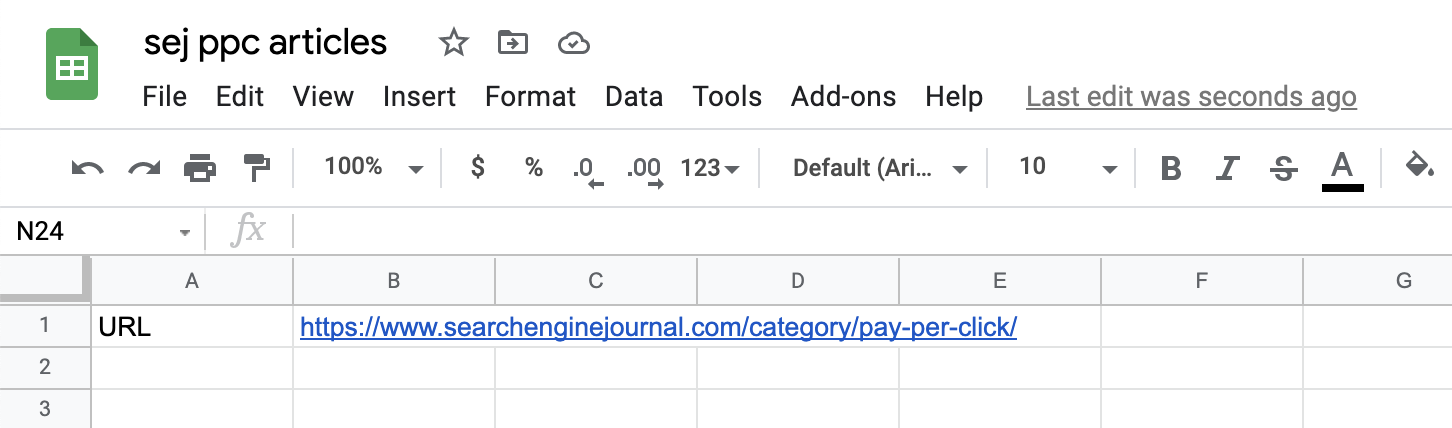
第 3 步:找到 XPath
我們找到要將其內容導入數據電子表格的元素的 XPath。
在我們的示例中,讓我們從最近 30 篇文章的標題開始。
前往 Chrome。將鼠標懸停在其中一篇文章的標題上后,右鍵單擊并選擇檢查。
SearchEngineJournal.com 的屏幕截圖,2021 年 7 月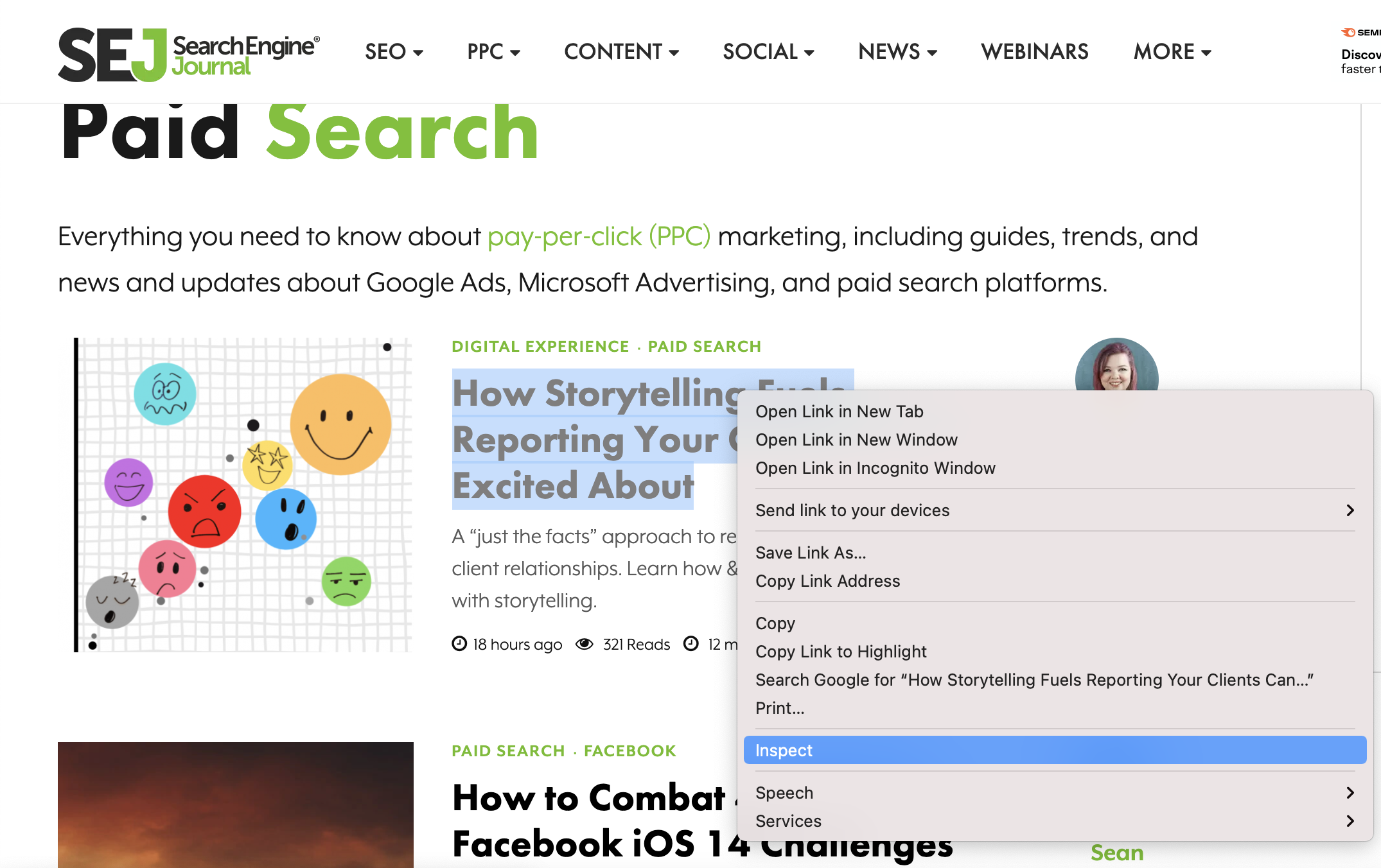
這將打開 Chrome 開發工具窗口:
SearchEngineJournal.com 的屏幕截圖,2021 年 7 月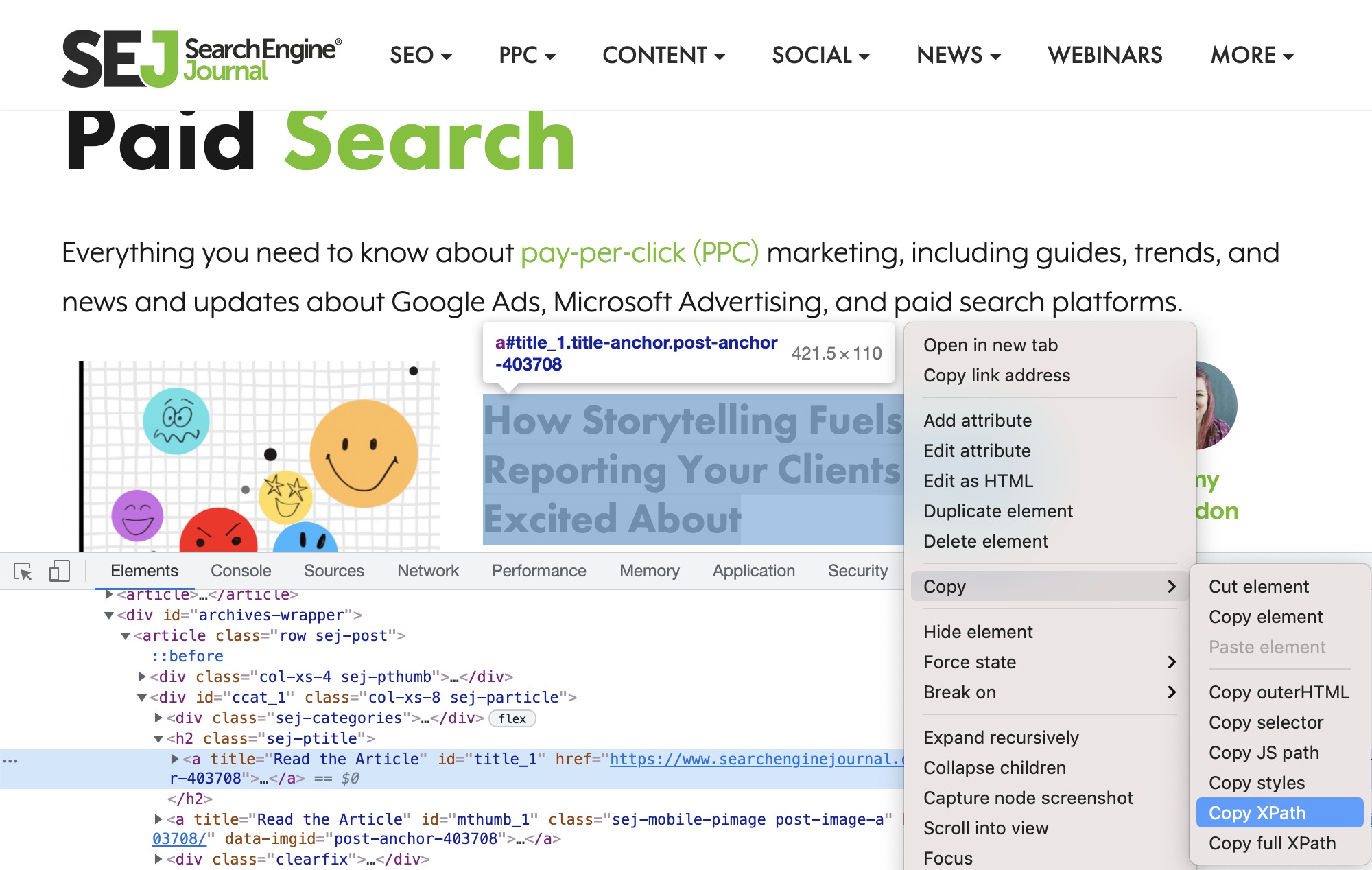
確保文章標題仍處于選中狀態并突出顯示,然后再次右鍵單擊并選擇“復制”>“復制 XPath”。
第 4 步:將數據提取到 Google 表格中
回到你的 Google Sheets 文檔中,引入 IMPORTXML 函數,如下所示:
=IMPORTXML(B1,”//*[開頭為(@id, ‘title’)]”)
有幾點需要注意:
首先,在我們的公式中,我們將頁面的 URL 替換為對存儲 URL 的單元格 (B1) 的引用。
其次,當從 Chrome 復制 XPath 時,這將始終用雙引號引起來。
(//*[@id=”title_1″])
但是,為了確保它不會破壞公式,需要將雙引號更改為單引號。
(//*[@id=’title_1′])
請注意,在這種情況下,因為每篇文章的頁面 ID 標題都會發生變化(title_1、title_2 等),我們必須稍微修改查詢并使用“starts-with”以捕獲頁面上 ID 包含的所有元素’標題。’
以下是 Google 表格文檔中的內容:
截取自 Google 表格的屏幕截圖,2021 年 7 月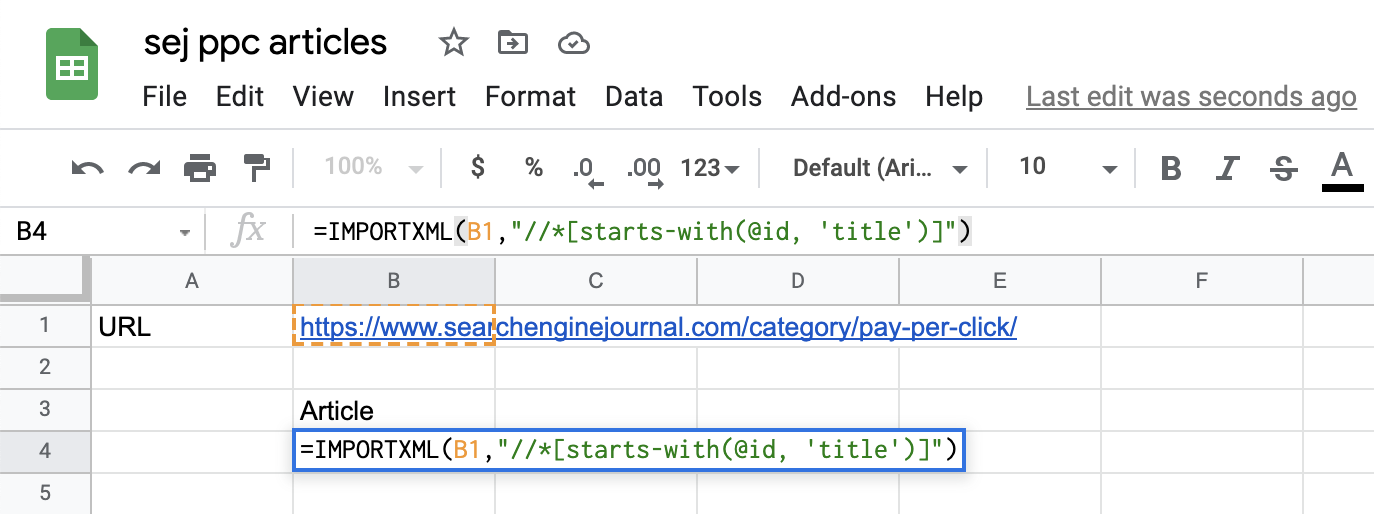
片刻之后,查詢將數據加載到電子表格后,結果如下所示:
截取自 Google 表格的屏幕截圖,2021 年 7 月
如您所見,該列表返回了我們剛剛抓取的頁面上的所有文章(包括我之前關于自動化以及如何使用廣告定制器提高 Google Ads 廣告系列效果的文章)。
您也可以將其應用于抓取設置廣告活動所需的任何其他信息。
讓我們將登陸頁面 URL、每篇文章的特色片段和作者姓名添加到我們的表格文檔中。
對于著陸頁 URL,我們需要調整查詢以指定我們在附加到文章標題的 HREF 元素之后。
因此,我們的查詢將如下所示:
=IMPORTXML(B1,”//*[開頭為(@id, ‘title’)]/@href”)
現在,將“/@href”附加到 Xpath 的末尾。
截取自 Google 表格的屏幕截圖,2021 年 7 月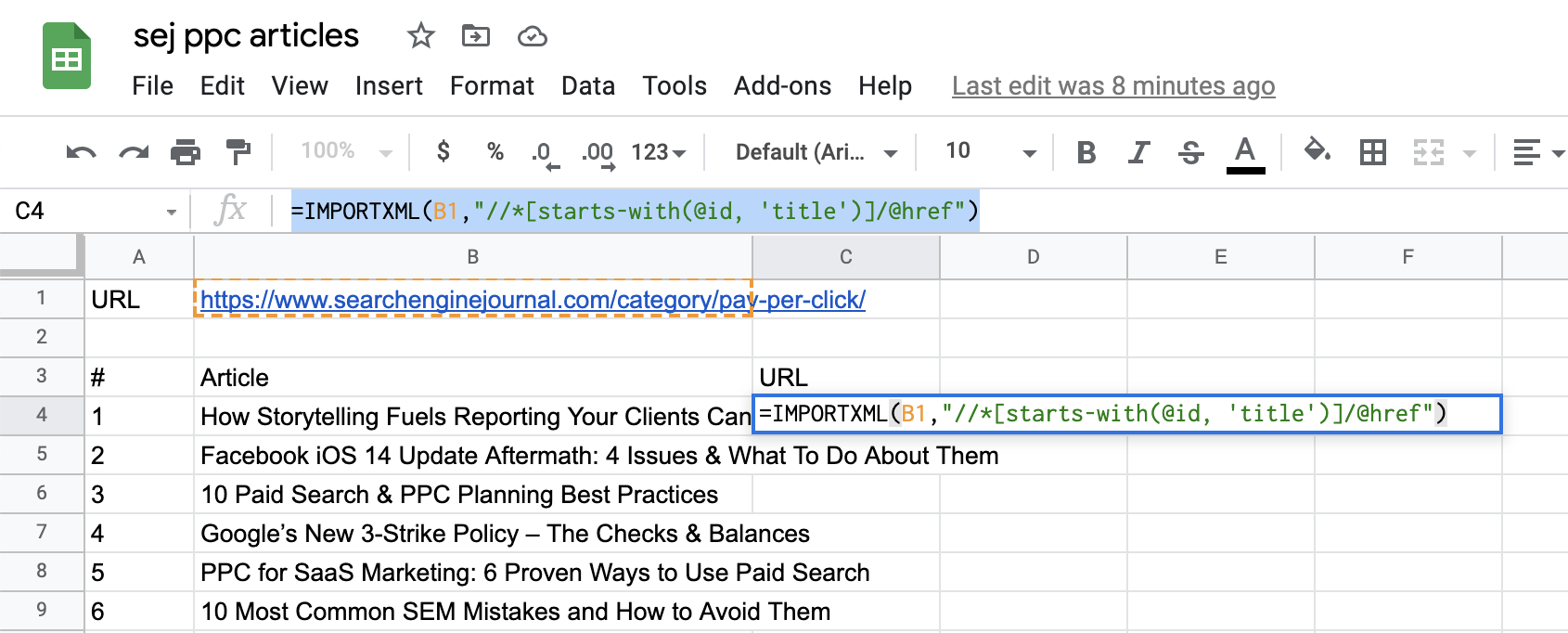
瞧!馬上,我們就有了著陸頁的 URL:
截取自 Google 表格的屏幕截圖,2021 年 7 月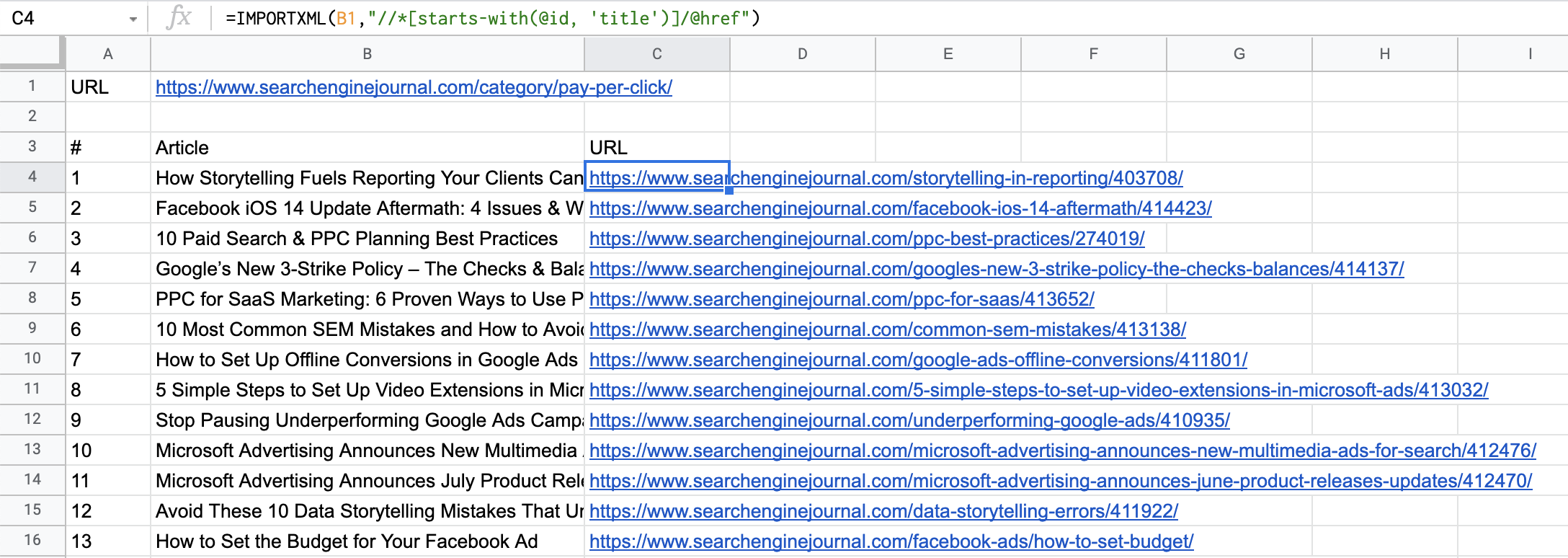
您可以對特色片段和作者姓名執行相同的操作:
截取自 Google 表格的屏幕截圖,2021 年 7 月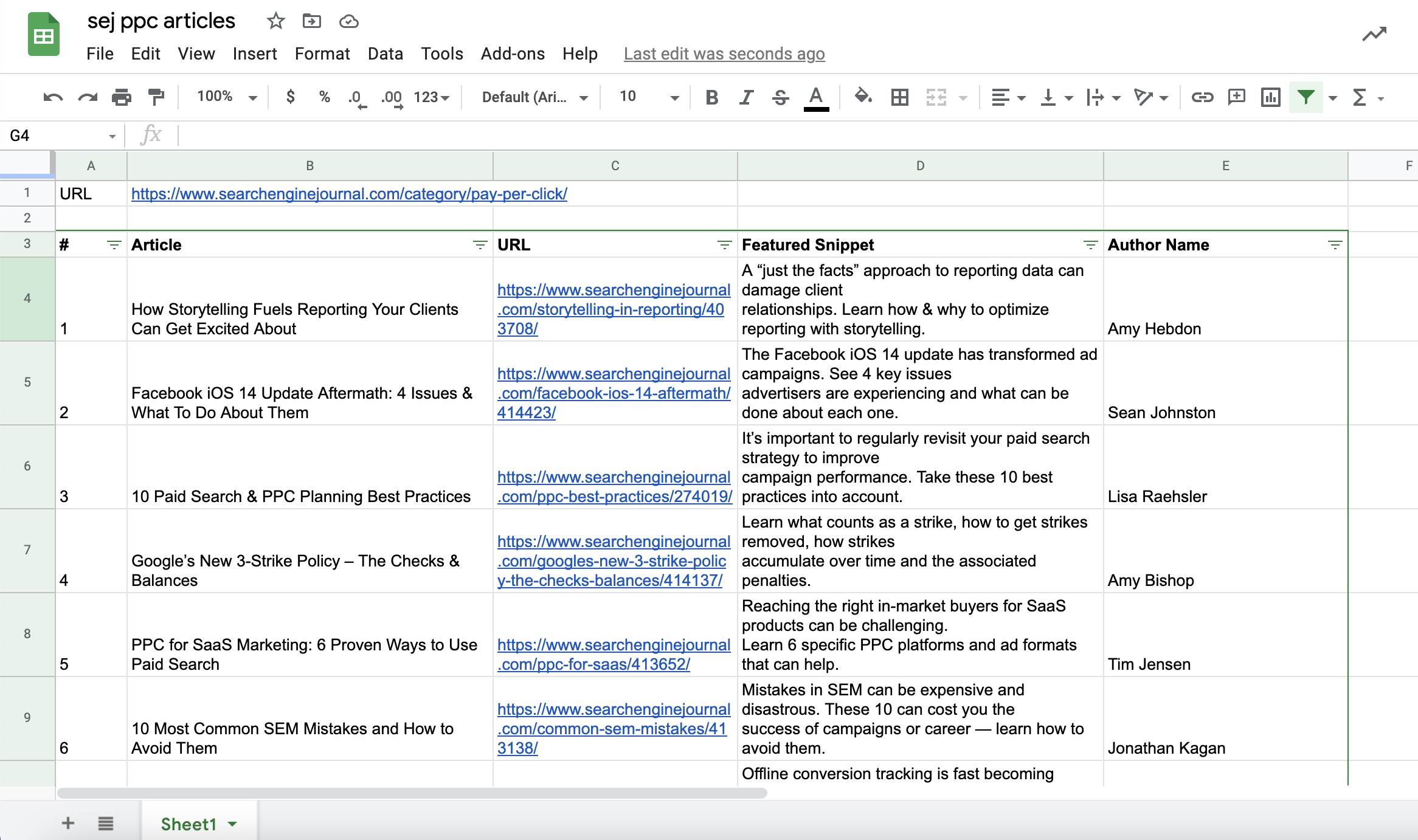
故障排除
需要注意的一件事是,為了能夠使用查詢返回的所有數據完全擴展和填充電子表格,填充數據的列必須有足夠的空閑單元格并且沒有其他數據擋道。
這與我們使用 ARRAYFORMULA 時的工作方式類似,要展開的公式必須在同一列中沒有其他數據。
結論
并且你有一個完全自動化、無錯誤的方式來從(可能)任何網頁上抓取數據,無論你需要內容和產品描述,還是電子商務數據,如產品價格或運費。
在信息和數據可以成為提供比平均結果更好所需的優勢的時代,以簡單快捷的方式抓取網頁和結構化內容的能力可能是無價的。此外,正如我們在上面看到的,IMPORTXML 可以幫助縮短執行時間并減少出錯的機會。
此外,該功能不僅是一個可以專門用于 PPC 任務的好工具,而且可以在許多需要網絡抓取的不同項目中真正有用,包括 SEO 和內容任務。
2021 SEJ 圣誕節倒計時:
- #12 – 新的 Google 業務簡介:本地 SEO 的完整指南
- #11 – 如何使用 Python 通過搜索意圖自動進行 SEO 關鍵字聚類
- #10 – 了解 Google Analytics 4:完整指南
- #9 – 我希望在我的 SEO 職業生涯中早點知道的 7 件事
- #8 – 針對 Google 新聞、頭條新聞和發現進行優化的指南
- #7 – 關鍵字集群:如何提升您的 SEO 內容策略
- #6 – 高級核心網絡生命力:技術 SEO 指南
- #5 – 如何使用 Google 表格進行網頁抓取和活動構建